Mini-o3 is an open-source model that delivers strong thinking-with-images capability, generating multi-turn agentic trajectories like OpenAI o3, with the interaction turns scaling up to tens of rounds. Full training recipe is open-source.
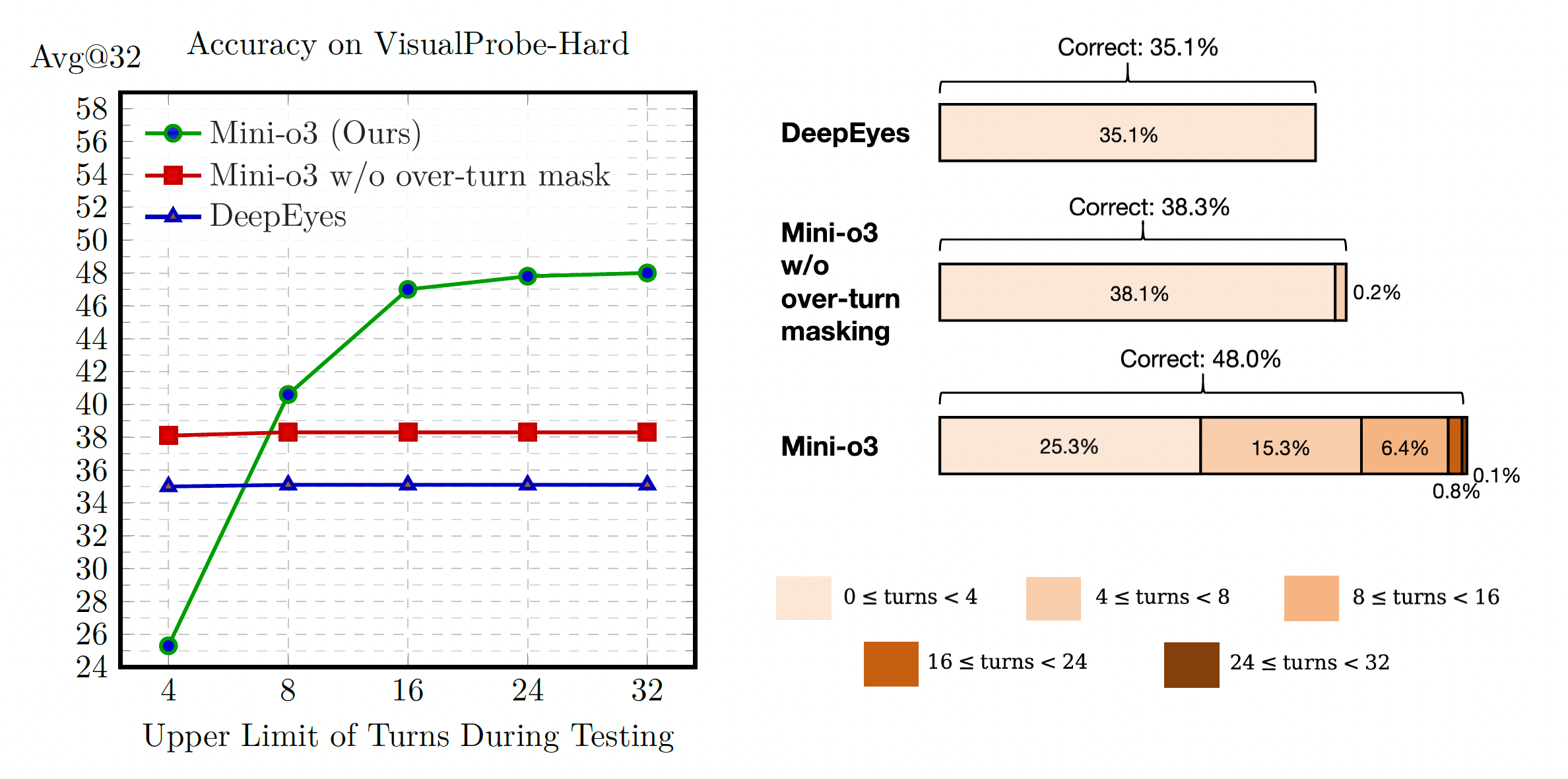
Recent advances in large multimodal models have leveraged image-based tools with reinforcement learning to tackle visual problems. However, existing open-source approaches often exhibit monotonous reasoning patterns and allow only a limited number of interaction turns, making them inadequate for difficult tasks that require trial-and-error exploration. In this work, we address this limitation by scaling up tool-based interactions and introduce Mini-o3, a system that executes deep, multi-turn reasoning—spanning tens of steps—and achieves state-of-the-art performance on challenging visual search tasks. Our full recipe for reproducing OpenAI o3–style behaviors is presented.
Training Mini-o3 includes two stages:
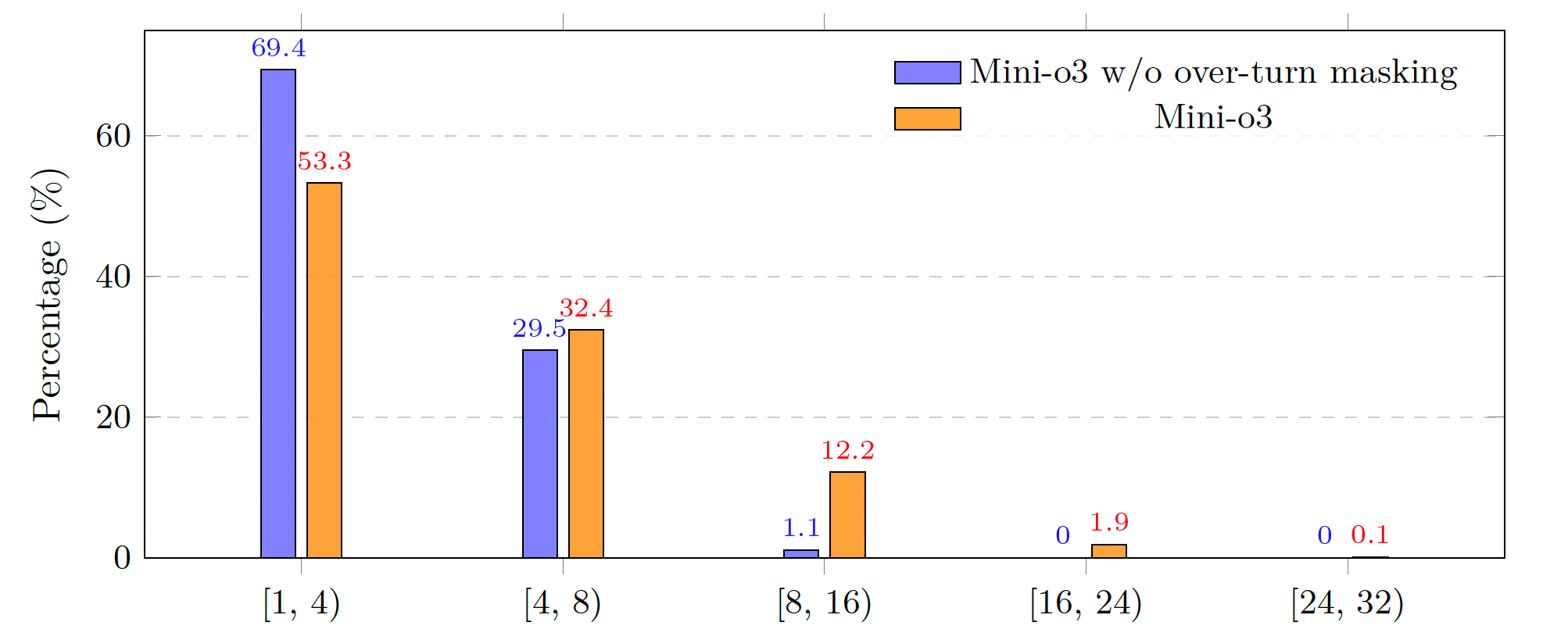
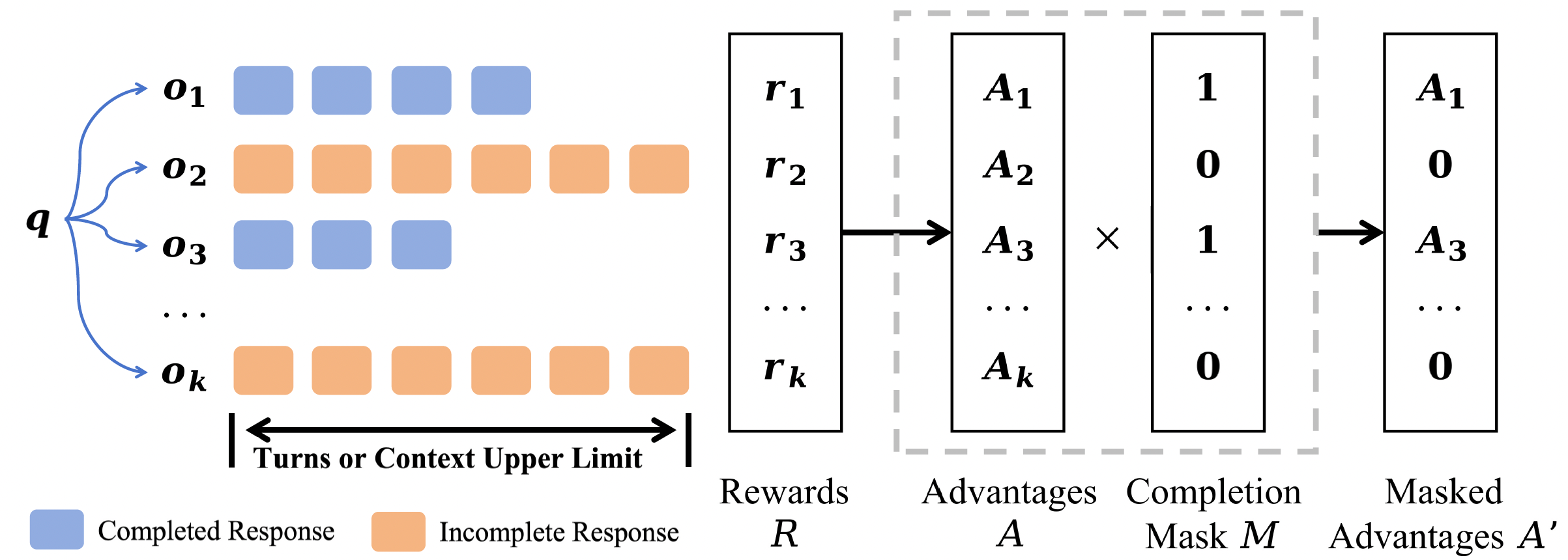
Hard instances are essential for encouraging reflective, trial-and-error reasoning during reinforcement learning. To this end, we construct a challenging visual search dataset, the Visual Probe Dataset (VisualProbe). It comprises 4,000 visual question–answer pairs for training and 500 pairs for testing, spanning three difficulty levels: easy, medium, and hard. Compared with prior visual search benchmarks, VisualProbe is characterized by:

 Demo
Demo

| Model | VisualProbe | V* Bench | HR-Bench | MME-Realworld | |||
|---|---|---|---|---|---|---|---|
| hard | medium | easy | 4K | 8K | |||
| GPT-4o | 11.2 | 15.4 | 47.5 | 65.2 | 62.0 | 58.3 | 45.2 |
| LLaVA-OneVision | 13.4 | 12.5 | 36.2 | 70.9 | 61.2 | 54.0 | 57.4 |
| Qwen2.5-VL-Instruct | 23.9 | 26.0 | 39.1 | 75.5 | 68.2 | 62.7 | 57.3 |
| SEAL† | – | – | – | 75.4 | – | – | – |
| DyFo† | – | – | – | 81.2 | – | – | – |
| Chain-of-Focus† | – | – | – | 88.0 | – | – | – |
| Pixel Reasoner‡ | 28.8 | 29.6 | 58.4 | 86.3 | 74.0 | 66.9 | 64.4 |
| DeepEyes‡ | 35.1 | 29.8 | 60.1 | 83.3 | 73.2 | 69.5 | 64.0 |
| Mini-o3 (Ours) | 48.0 | 50.4 | 67.0 | 88.2 | 77.5 | 73.3 | 65.5 |
This website is adapted from Nerfies and LLaVA, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the Qwen team for giving us access to their models, and open-source projects, including V* Bench and DeepEyes.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of Qwen and Gemini-2.5-Pro. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.